CNN 2 (Schrauben)
Contents
CNN 2 (Schrauben)¶
import numpy as np
from numpy import load
from sklearn.preprocessing import OneHotEncoder
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import load_model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.utils import plot_model
from myst_nb import glue
Datensatz laden¶
X_train = load('../01_Dataset/Dataset_224x224/X_train.npy').astype(np.float32).reshape(-1, 224,224,1)
y_train = load('../01_Dataset/Dataset_224x224/y_train.npy')
X_test=load('../01_Dataset/Dataset_224x224/X_test.npy').astype(np.float32).reshape(-1,224,224,1)
y_test=load('../01_Dataset/Dataset_224x224/y_test.npy').astype(np.int32)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('X_train shape:'+ str(X_train.shape))
print('y_train shape:'+ str(y_train.shape))
X_train shape:(7560, 224, 224, 1)
y_train shape:(7560, 6)
Bilder anzeigen¶
import matplotlib.pyplot as plt
from matplotlib import gridspec
nrow = 5
ncol = 5
fig = plt.figure(figsize=(24, 24))
gs = gridspec.GridSpec(nrow, ncol,
wspace=0.0, hspace=0.0,
top=1.-0.5/(nrow+1), bottom=0.5/(nrow+1),
left=0.5/(ncol+1), right=1-0.5/(ncol+1))
im = 0
for i in range(nrow):
for j in range(ncol):
ax= plt.subplot(gs[i,j])
ax.imshow(X_train[im,:,:,0],cmap='gray')
ax.set_xticklabels([])
ax.set_yticklabels([])
im +=1
plt.show()

Vergleich der CNN Modelle¶
# Modell Aufbau
model = Sequential()
model.add(Conv2D(10, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 1)))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern:
if os.path.isfile('models/1Conv2d_10_3x3_relu.h5') is False:
model.save('models/1Conv2d_10_3x3_relu.h5')
np.save('models/1Conv2d_10_3x3_relu.npy',history.history)
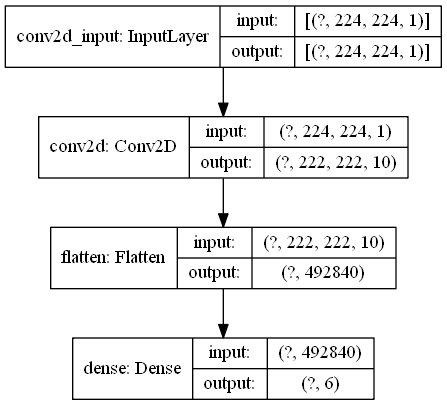
|
|
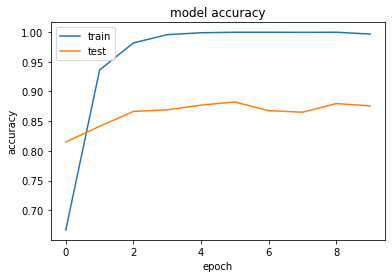
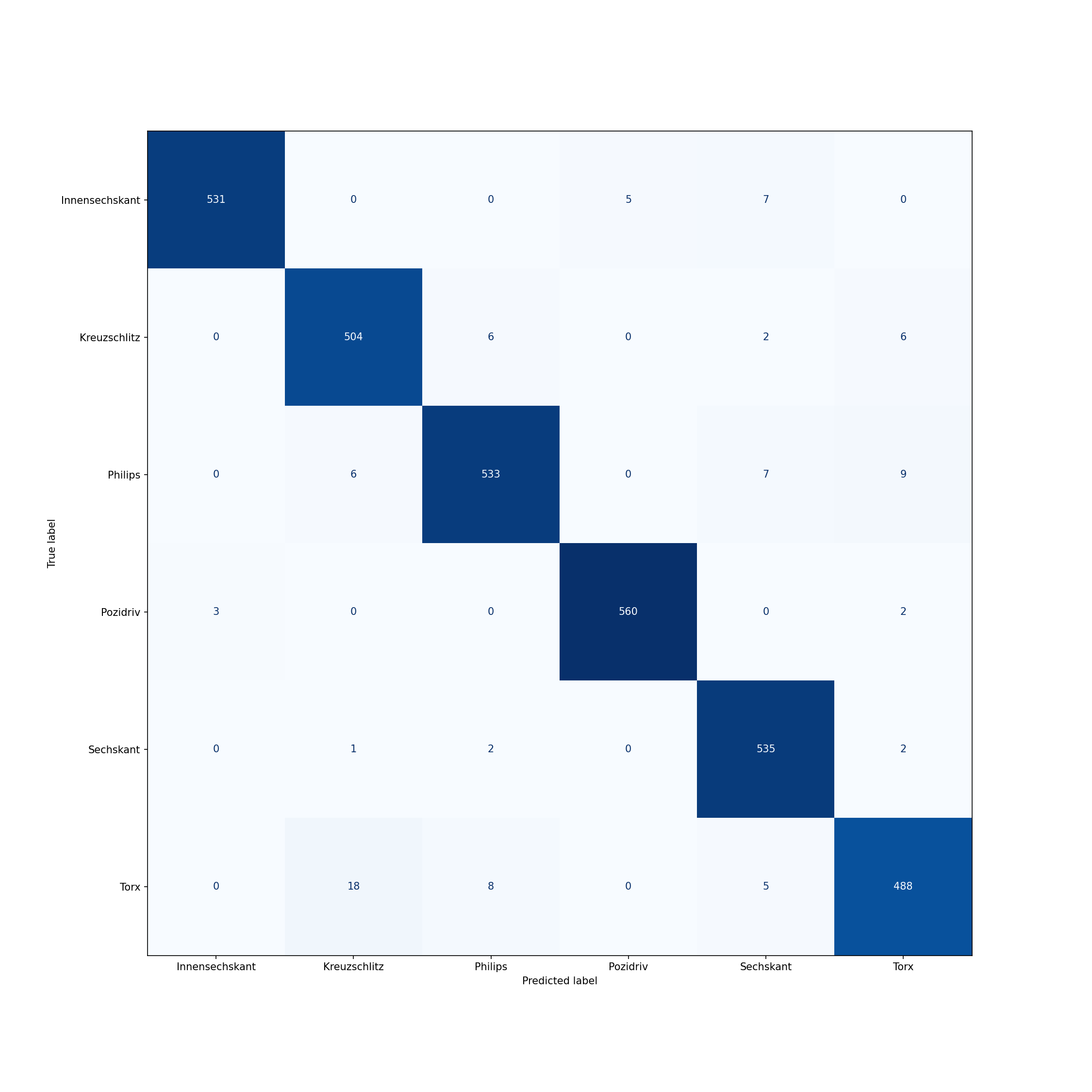
\(~\)
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(10, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 1)))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=30, batch_size=100)
# Modell Speichern
if os.path.isfile('models/1Conv2d_10_3x3_relu_Ep=30.h5') is False:
model.save('models/1Conv2d_10_3x3_relu_Ep=30.h5')
np.save('models/1Conv2d_10_3x3_relu_Ep=30.npy',history.history)
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(10, kernel_size=(3, 3), activation="relu", input_shape=(224,224,1,)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern
if os.path.isfile('models/1Conv2d_10_3x3_MaxP_2x2.h5') is False:
model.save('models/1Conv2d_10_3x3_MaxP_2x2.h5')
np.save('models/1Conv2d_10_3x3_MaxP_2x2.npy',history.history)
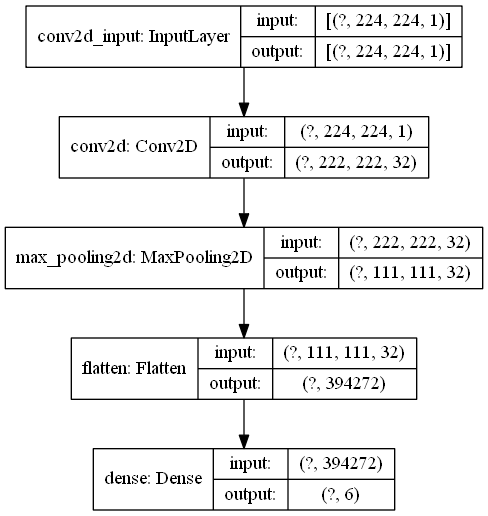
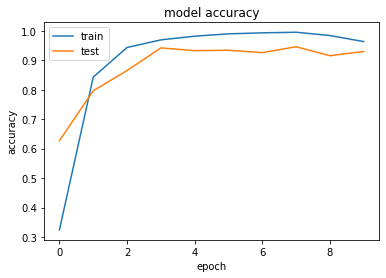
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(224,224,1,)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern
if os.path.isfile('models/1Conv2d_32_3x3_MaxP_2x2.h5') is False:
model.save('models/1Conv2d_32_3x3_MaxP_2x2.h5')
np.save('models/history_1Conv2d_32_3x3_MaxP_2x2.npy',history.history)
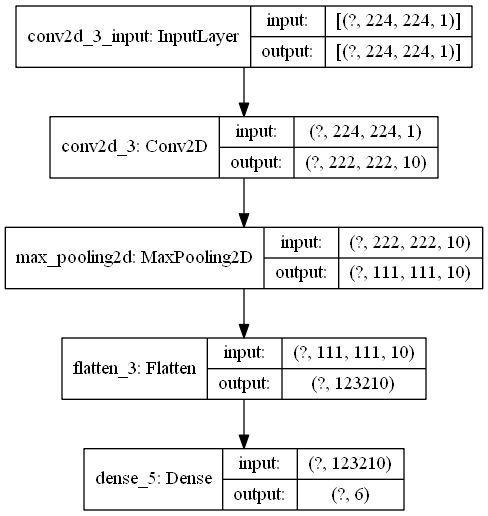
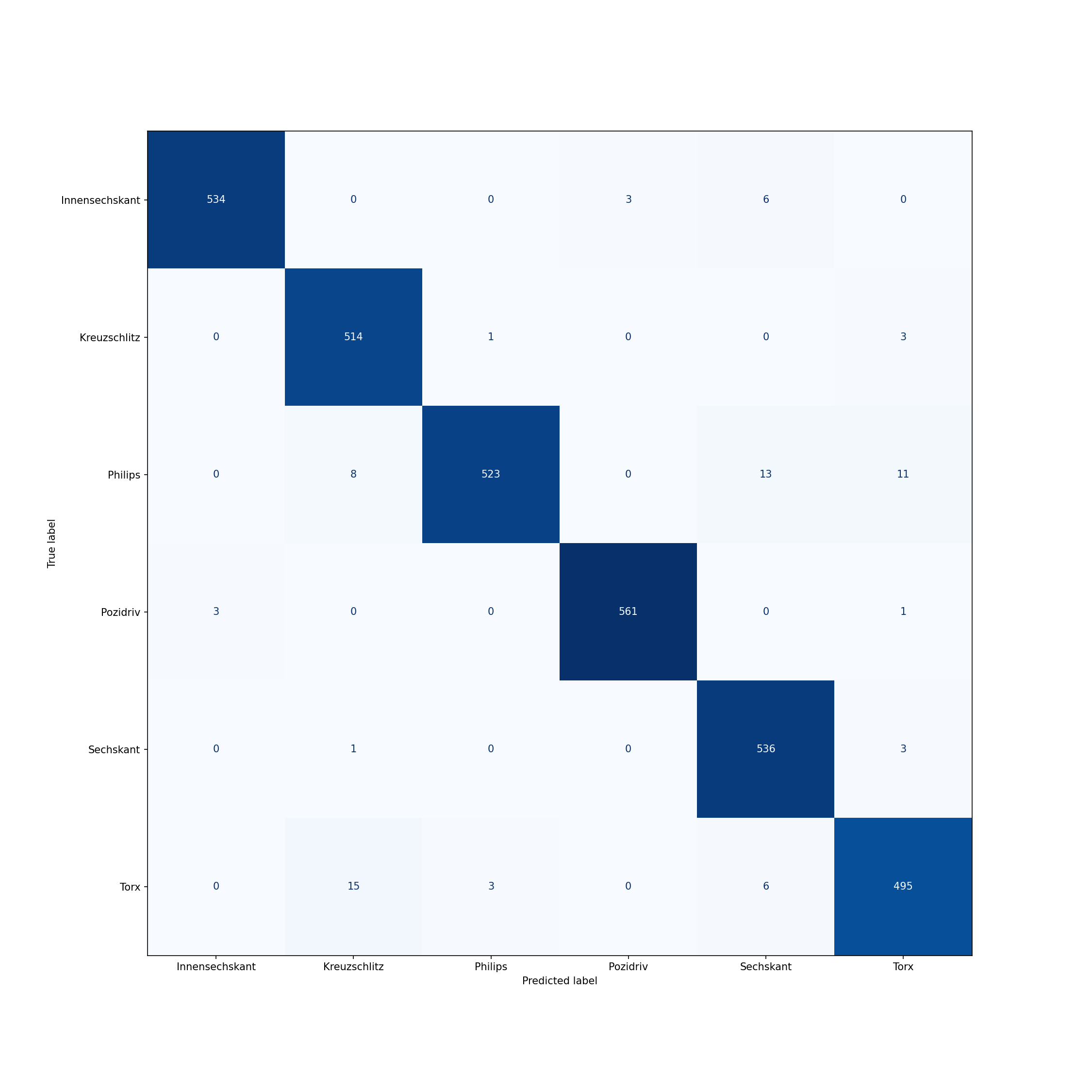
|
|
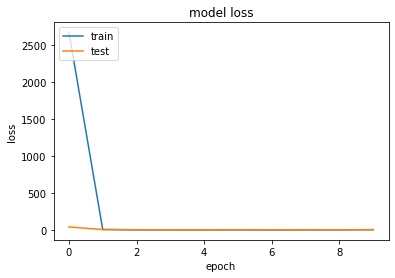
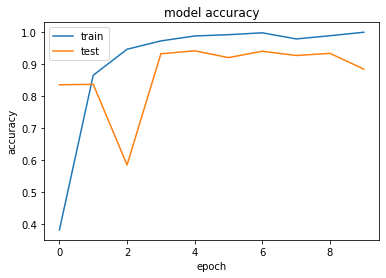
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu", input_shape=(224,224,1,)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern
if os.path.isfile('models/1Conv2d_64_3x3_MaxP_2x2.h5') is False:
model.save('models/1Conv2d_64_3x3_MaxP_2x2.h5')
np.save('models/history_1Conv2d_64_3x3_MaxP_2x2.npy',history.history)
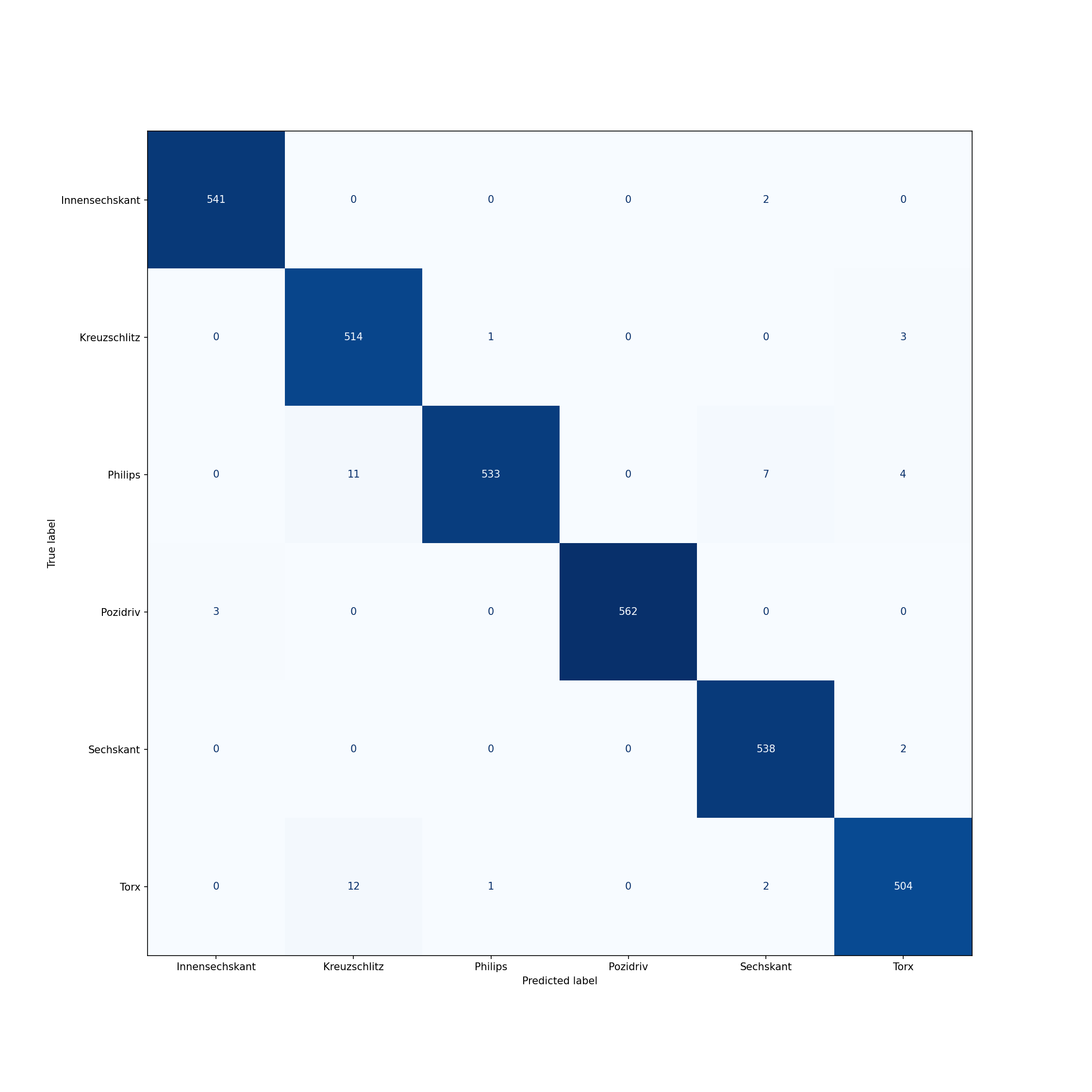
|
|
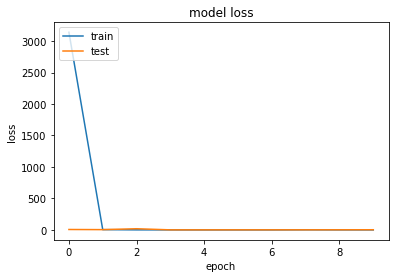
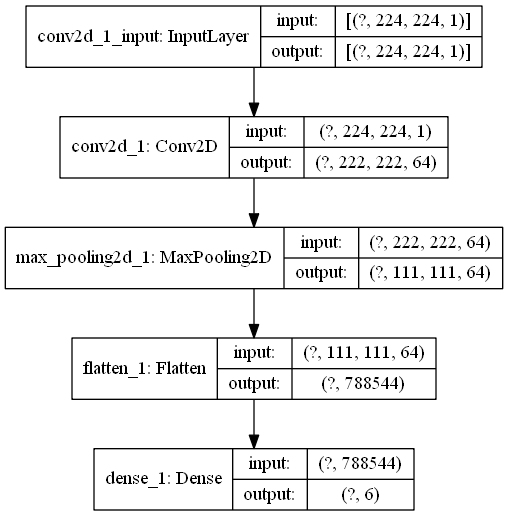
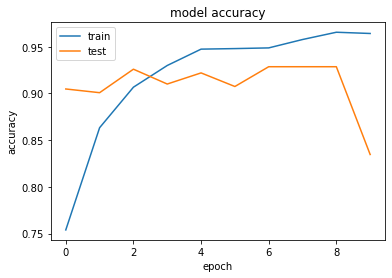
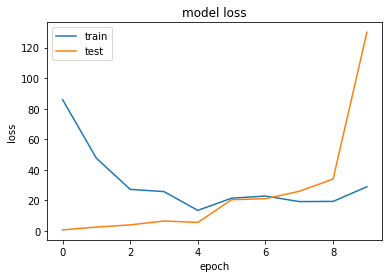
Dropout¶
Es könnte sein, dass das CNN bestimmte Verbindungen besonders hoch gewichtet wie z.\(~\)B Bildinhalte, die nicht zum Objekt gehören. Mit Dropout werden Verbindungen unterbrochen, womit das Training „erschwert“ wird. Das bringt ein robusteres Modell hervor, welches auf den Testdaten eine höhere Genauigkeit erreicht. Gerade bei vielen Features soll sich das CNN nicht nur auf wenige Merkmale „fixieren“, obwohl dies zu einer höheren Trainingsgenauigkeit führen würde.
# Modell Aufbau
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern
if os.path.isfile('models/2Conv2d_1MaxP_1dropout.h5') is False:
model.save('models/2Conv2d_1MaxP_1dropout.h5')
np.save('models/history_2Conv2d_1MaxP_1dropout.npy',history.history)
|
|
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 1)))
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=10, batch_size=100)
# Modell Speichern
if os.path.isfile('models/4Conv2d_2MaxP_2dropout.h5') is False:
model.save('models/4Conv2d_2MaxP_2dropout.h5')
np.save('models/history_4Conv2d_2MaxP_2dropout.npy',history.history)
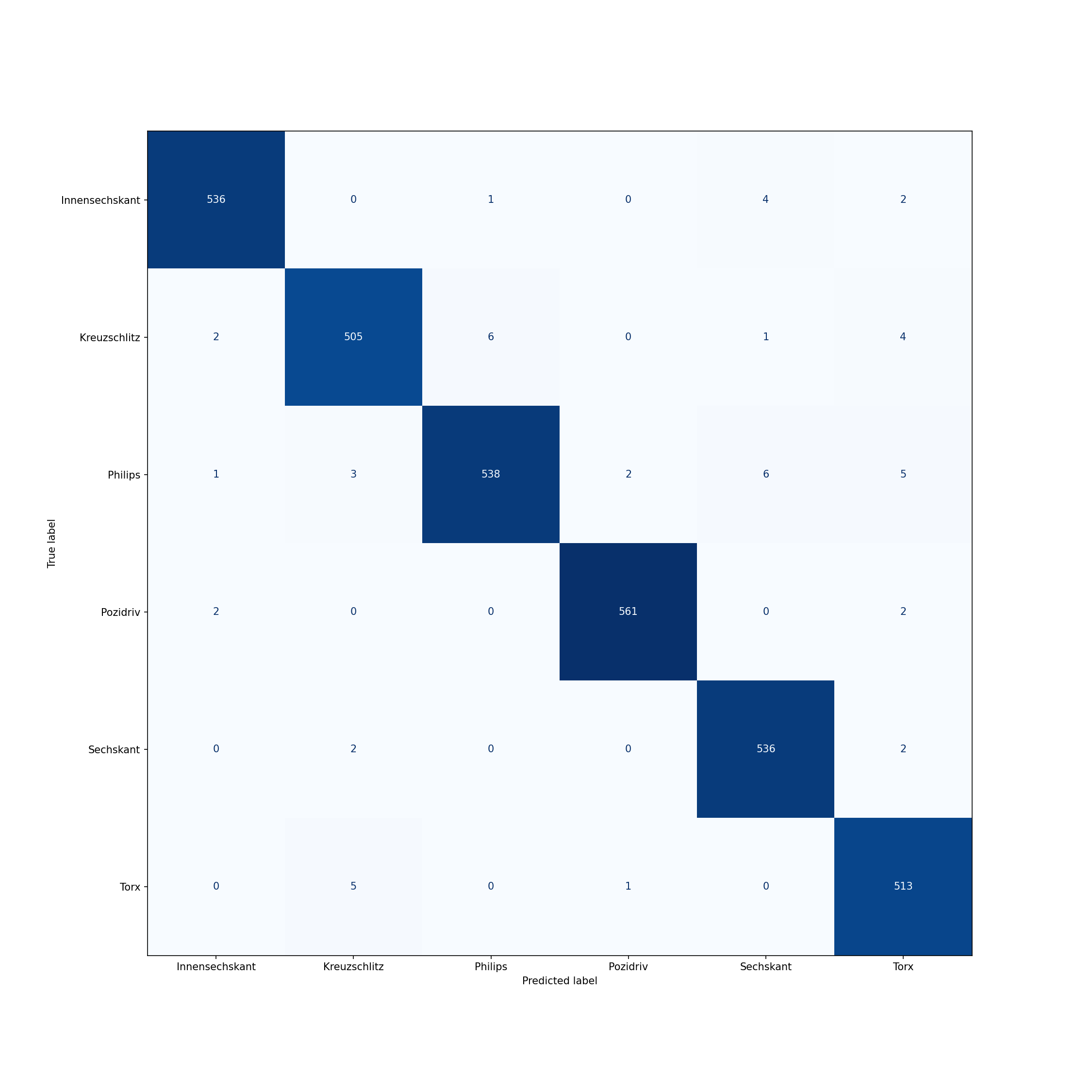
|
|
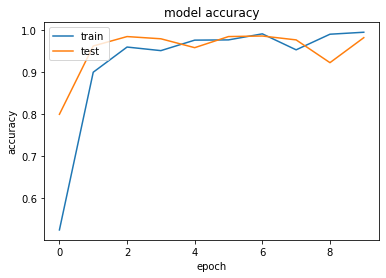
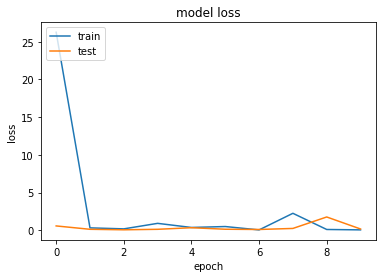
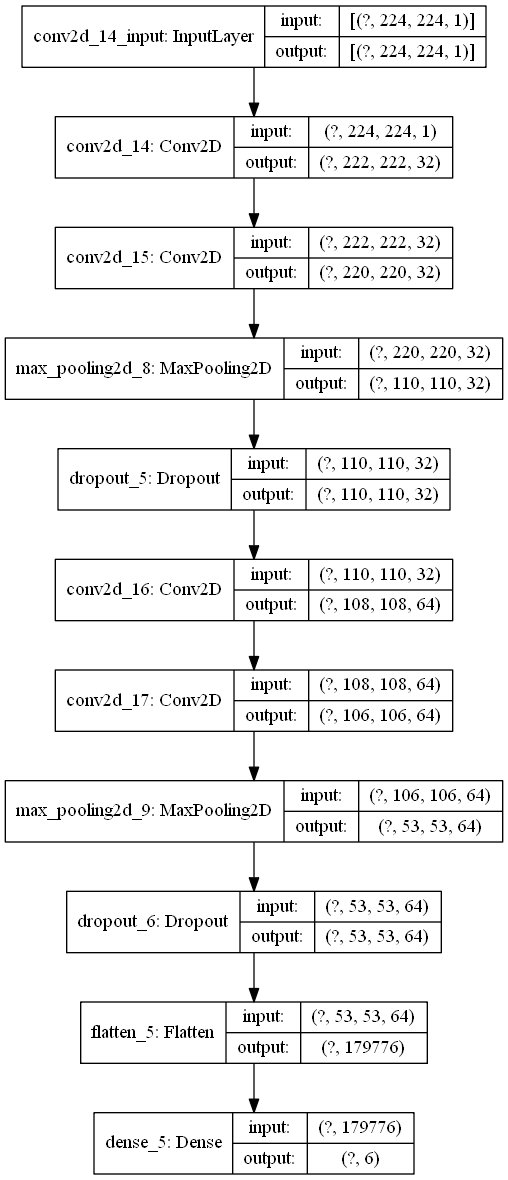
\(~\)
# Modell Aufbau
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 1)))
model.add(Conv2D(32, kernel_size=(3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(Conv2D(64, kernel_size=(3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(6, activation="softmax"))
# Modell trainieren
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_split=0.1, epochs=20, batch_size=100)
# Modell Speichern
if os.path.isfile('models/4Conv2d_2MaxP_2dropout_Ep=20.h5') is False:
model.save('models/4Conv2d_2MaxP_2dropout_Ep=20.h5')
np.save('models/history_4Conv2d_2MaxP_2dropout_Ep=20.npy',history.history)
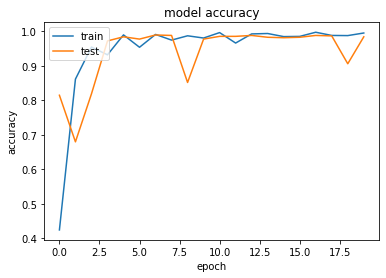
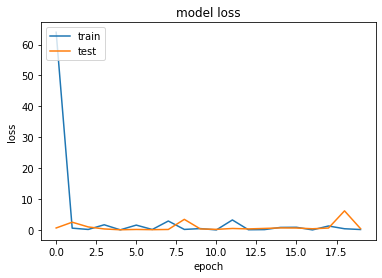
|
|
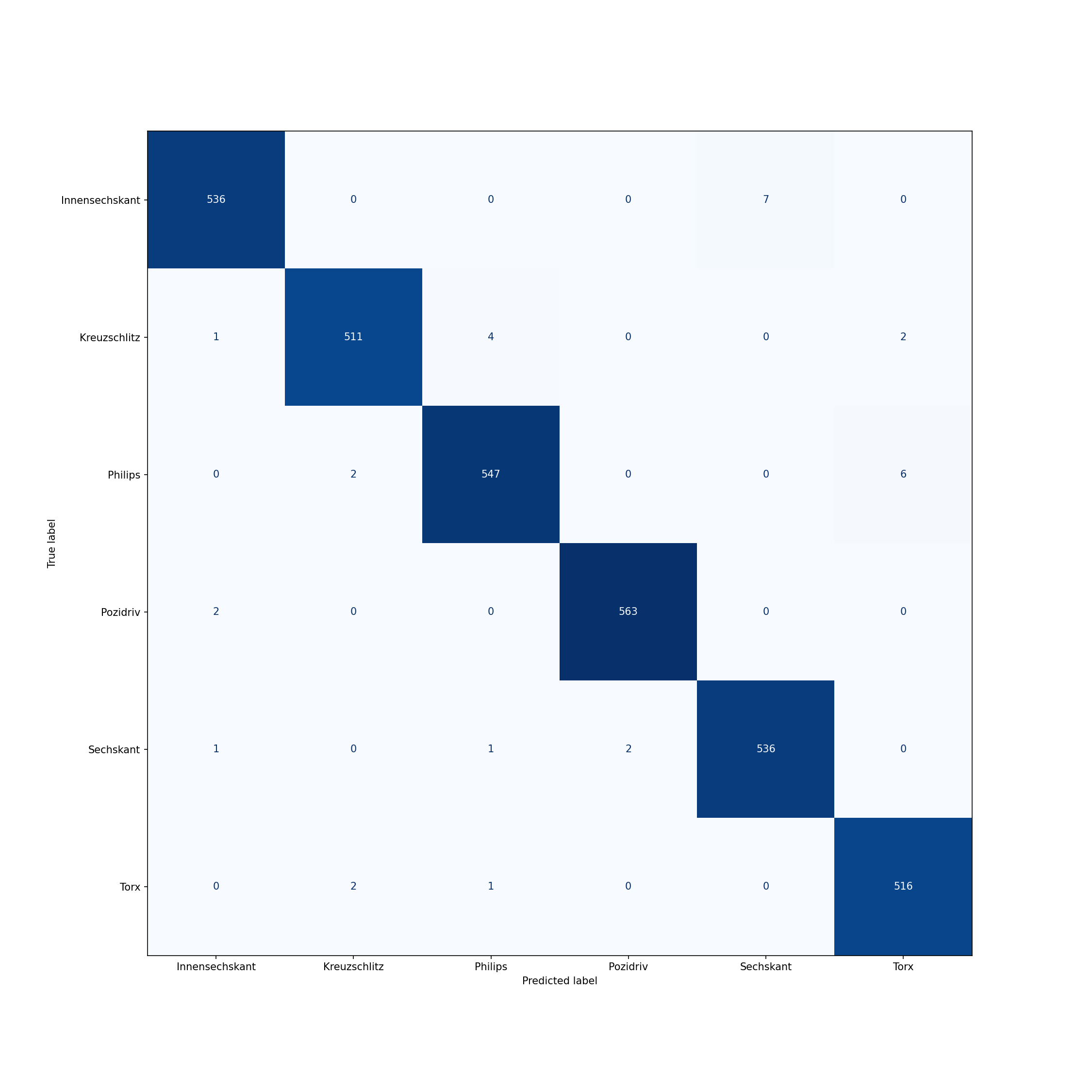
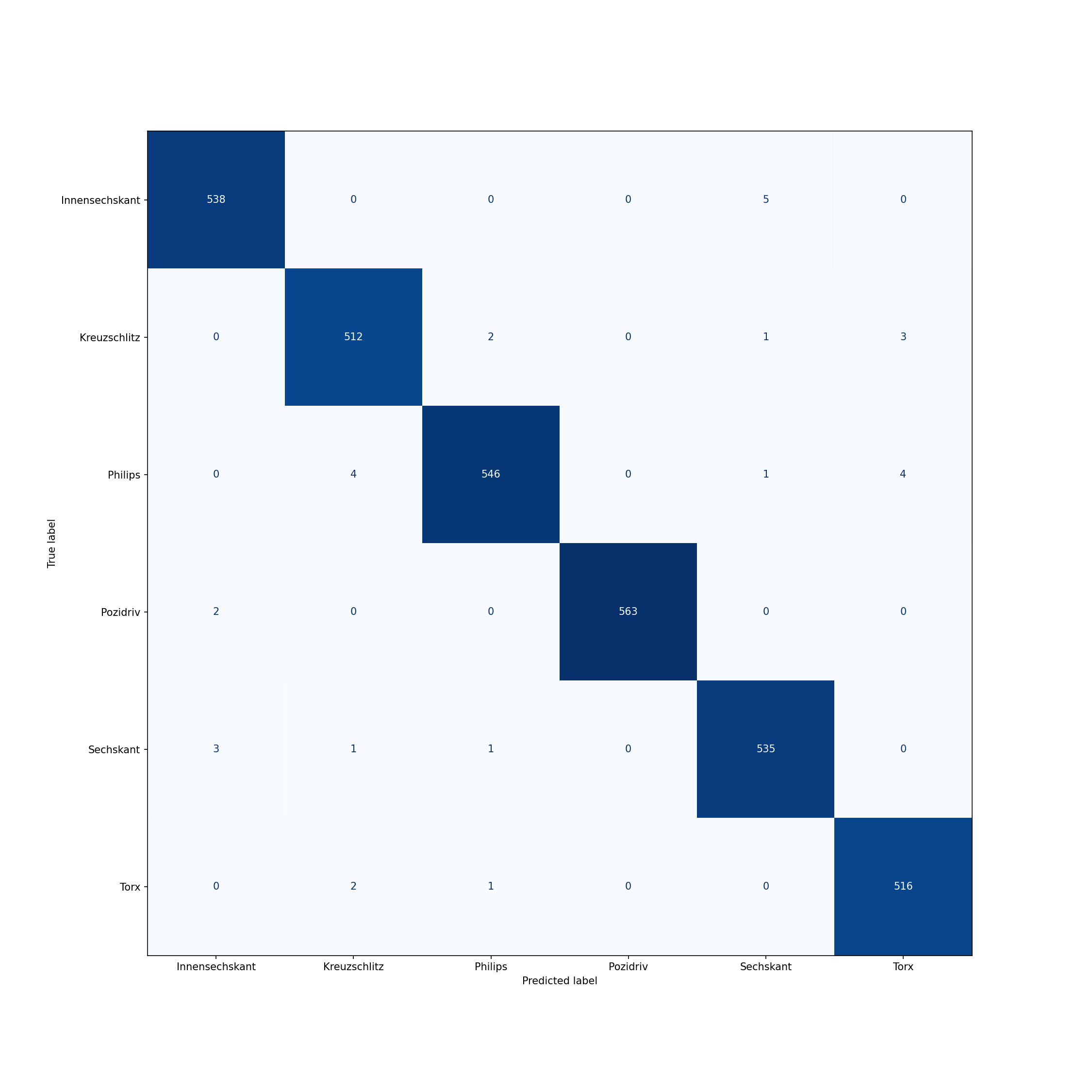
Fazit¶
Das Ziel dieser Masterarbeit war es, mit Hilfe von künstlichen neuronalen Netzen, eine Bilderkennung zu entwickeln. Dabei hat sich gezeigt, dass die Beschaffung der Daten für einen Trainingsdatensatz, den größten Anteil am Gesamtaufwand ausmacht.
Für die Anwendung in einem Sortierroboter, sollten die Modelle unabhängig von der Beleuchtung und dem Schattenwurf, in der Lage sein, die Schrauben zu erkennen.
In dieser Arbeit, die den Weg für Weiterentwicklungen bereiten sollte, wurden eine Beleuchtungsstation entwickelt um einen Schattenwurf zu vermeiden.